
Continuous doesn’t mean slow
Once a lab trains AI that can fully replace its human employees, it will be able to multiply its workforce 100,000x. If these AIs do AI research, they could develop vastly superhuman systems in under a year.
There’s a lot of disagreement about how likely AI is to end up overthrowing humanity. Thoughtful pundits vary from <5% to >90%. What’s driving this disagreement?
One factor that often comes up in discussions is takeoff speeds, which Ajeya mentioned in the previous post. How quickly and suddenly do we move from today’s AI, to “expert-human level” AI[1], to AI that is way beyond human experts and could easily overpower humanity?
The final stretch — the transition from expert-human level AI to AI systems that can easily overpower all of us — is especially crucial. If this final transition happens slowly, we could potentially have a long time to get used to the obsolescence regime and use very competent AI to help us solve AI alignment (among other things). But if it happens very quickly, we won’t have much time to ensure superhuman systems are aligned, or to prepare for human obsolescence in any other way.
Scott Alexander is optimistic that things might move gradually. In a recent ACX post titled ‘Why I Am Not (As Much Of) A Doomer (As Some People)’, he says:
So far we’ve had brisk but still gradual progress in AI; GPT-3 is better than GPT-2, and GPT-4 will probably be better still. Every few years we get a new model which is better than previous models by some predictable amount.
Some people (eg Nate Soares) worry there’s a point where this changes… Maybe some jump… could take an AI from IQ 90 to IQ 1000 with no (or very short) period of IQ 200 in between…
I’m optimistic because the past few years have provided some evidence for gradual progress.
I agree with Scott that recent AI progress has been continuous and fairly predictable, and don’t particularly expect a break in that trend. But I expect the transition to superhuman AI to be very fast, even if it’s continuous.
The amount of “compute” (i.e. the number of AI chips) needed to train a powerful AI is much bigger than the amount of compute needed to run it. I estimate that OpenAI has enough compute to run GPT-4 on hundreds of thousands of tasks at once.[2]
This ratio will only become more extreme as models get bigger. Once OpenAI trains GPT-5 it’ll have enough compute for GPT-5 to perform millions of tasks in parallel, and once they train GPT-6 it’ll be able to perform tens of millions of tasks in parallel.[3]
Now imagine that GPT-6 is as good at AI research as the average OpenAI researcher.[4] OpenAI could expand their AI researcher workforce from hundreds of experts to tens of millions. That’s a mind-boggling large increase, a factor of 100,000. It’s like going from 1000 people to the entire US workforce. What’s more, these AIs could work tirelessly through the night and could potentially “think” much more quickly than human workers.[5] (This change won’t happen all-at-once. I expect speed-ups from less capable AI before this point, as Ajeya wrote in the previous post.)
How much faster would AI progress be in this scenario? It’s hard to know. But my best guess, from my recent report on takeoff speeds, is that progress would be much much faster. I think that less than a year after AI is expert-human level at AI research, AI could improve to the point of being able to easily overthrow humanity.
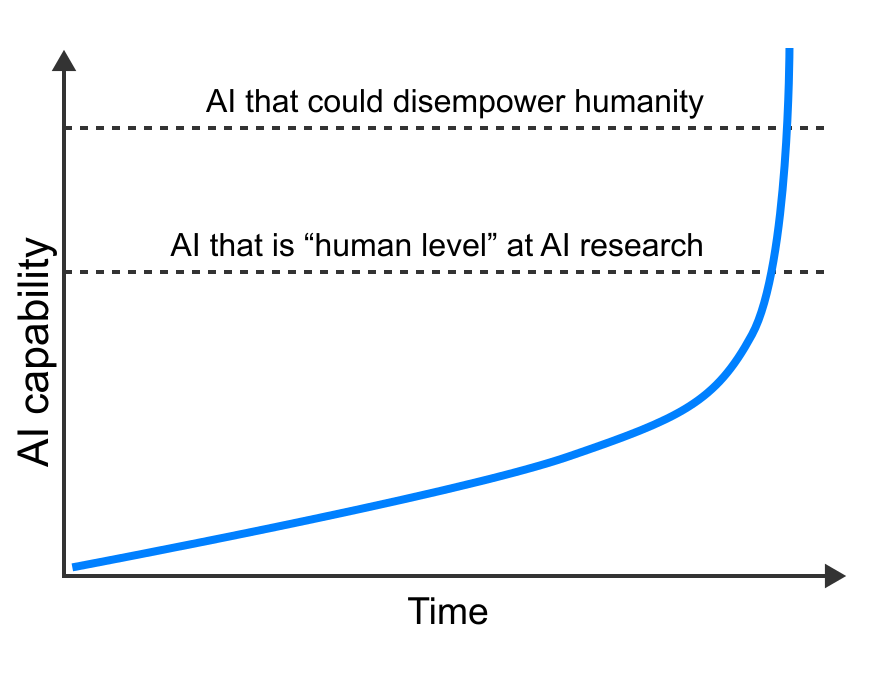
This is much faster than the timeline mentioned in the ACX post:
if you’re imagining specific years, imagine human-genius-level AI in the 2030s and world-killers in the 2040s
The cause of this fast transition isn’t that there’s a break in the trend of continuous progress. It’s that expert-human-level AI massively accelerates AI progress, causing this continuous progress to happen at a blistering pace.
Of course, this isn’t inevitable. Labs could choose not to use AI to accelerate AI progress, at least once AI gets sufficiently powerful. But it will be a tempting move, and they’re more likely to be cautious if they make specific and verifiable commitments in advance to pause AI progress.
I’m operationalizing “expert-human level AI” as “each forward pass of the AI produces as much useful output as 0.1 seconds of thought from a human expert”. It’s possible that AI will produce expert-level output by having many dumber AIs working together and thinking for much longer than a human expert would, but under my definition that wouldn’t count as expert-level AI because the quality of the AI’s thinking is below expert level. ↩︎
My calculation assumes that GPT-4 processes ten tokens per second on each task that it’s being applied to. Here’s how my estimate works: the training compute for GPT-4 has been estimated at ~3e25 total FLOP (source, h/t Epoch). I assume the training took 4 months, implying that amount of compute used per second during training was 3e18 FLOP/s. How many instances of GPT-4 could you run with this compute? If GPT-4 was trained with 3e25 FLOP in accordance with Chinchilla scaling, that implies it will require ~1e12 FLOP per forward pass. So you could do 3e18/1e12 = ~3e6 forward passes per second. In other words, you could run GPT-4 on ~3 million tasks in parallel, with it processing one token per second on each task, or on ~300,000 tasks in parallel at ten tokens per second.
Though there wouldn’t be enough memory to store 300,000 separate copies of the weights, this calculation suggests that there would be enough processing power to apply those weights to 300,000 different word generation tasks per second. (Each copy of the weights can perform many tasks in parallel.) ↩︎I make the simple assumption that GPT-5 will be the same as GPT-4 except for having 10X the parameters and being trained on 10X the data, and that GPT-6 will have an additional 10X parameters and 10X data. ↩︎
More precisely, assume that each forward pass of GPT-6 is as useful for advancing AI capabilities as 0.1 seconds of thought by an average OpenAI researcher. I.e. if OpenAI has 300 capabilities researchers today, then you could match their total output by running 300 copies of GPT-6 in parallel and having each of them produce 10 tokens per second. ↩︎
Rather than 10 million AIs thinking at human speed, OpanAI could potentially have 1 million AIs thinking 10X faster than a human, or 100,000 AIs thinking 100X faster. ↩︎