
AI predictions for 2026
But first, scoring my predictions for 2025

On December 13th, 2024, I registered predictions about what would happen with AI by the end of 2025, using this survey run by Sage. They asked five questions about benchmarks, four about the OpenAI Preparedness Framework risk categories, one about revenues, and one about public salience of AI.
The Sage team has updated the survey with the resolutions, so I went through and looked back at what I said. Overall, I was somewhat too bullish about benchmarks scores and much too bearish about AI revenue — the reverse of the conventional wisdom that people underestimate benchmark progress and overestimate real-world utility (something which I felt like I’ve done in previous years, though I didn’t register clear predictions so it’s hard to say).
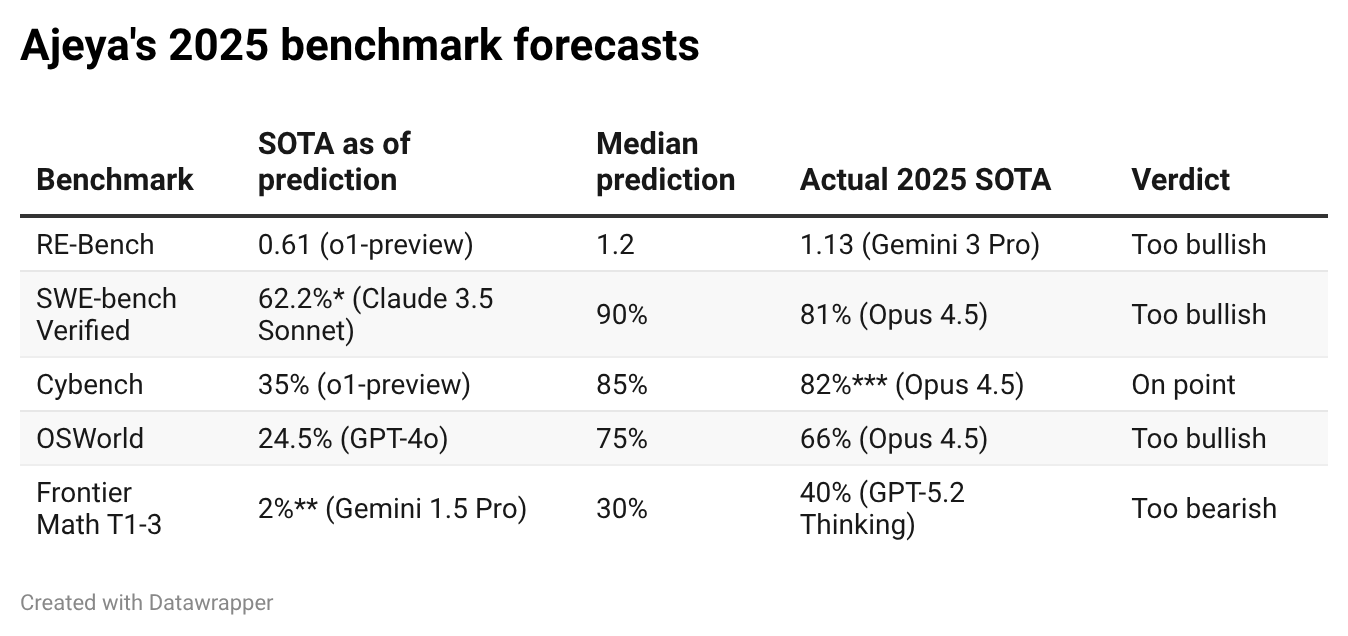
You can see how I did on benchmark scores in the table below.1 I overestimated progress on pretty much every benchmark other than FrontierMath Tiers 1-3,2 which notoriously jumped from ~2% to ~24% with the announcement of OpenAI’s o3, about a week after I registered my prediction (and less than two months after the benchmark was published).
All the other questions are in the table below. I did fine on the OpenAI Preparedness Framework predictions and was somewhat too bullish on public salience. But I completely bombed the annualized revenue question, predicting that it would merely triple from ~$4.5B to ~$17B instead of nearly 7xing (!) to ~$30.5B.
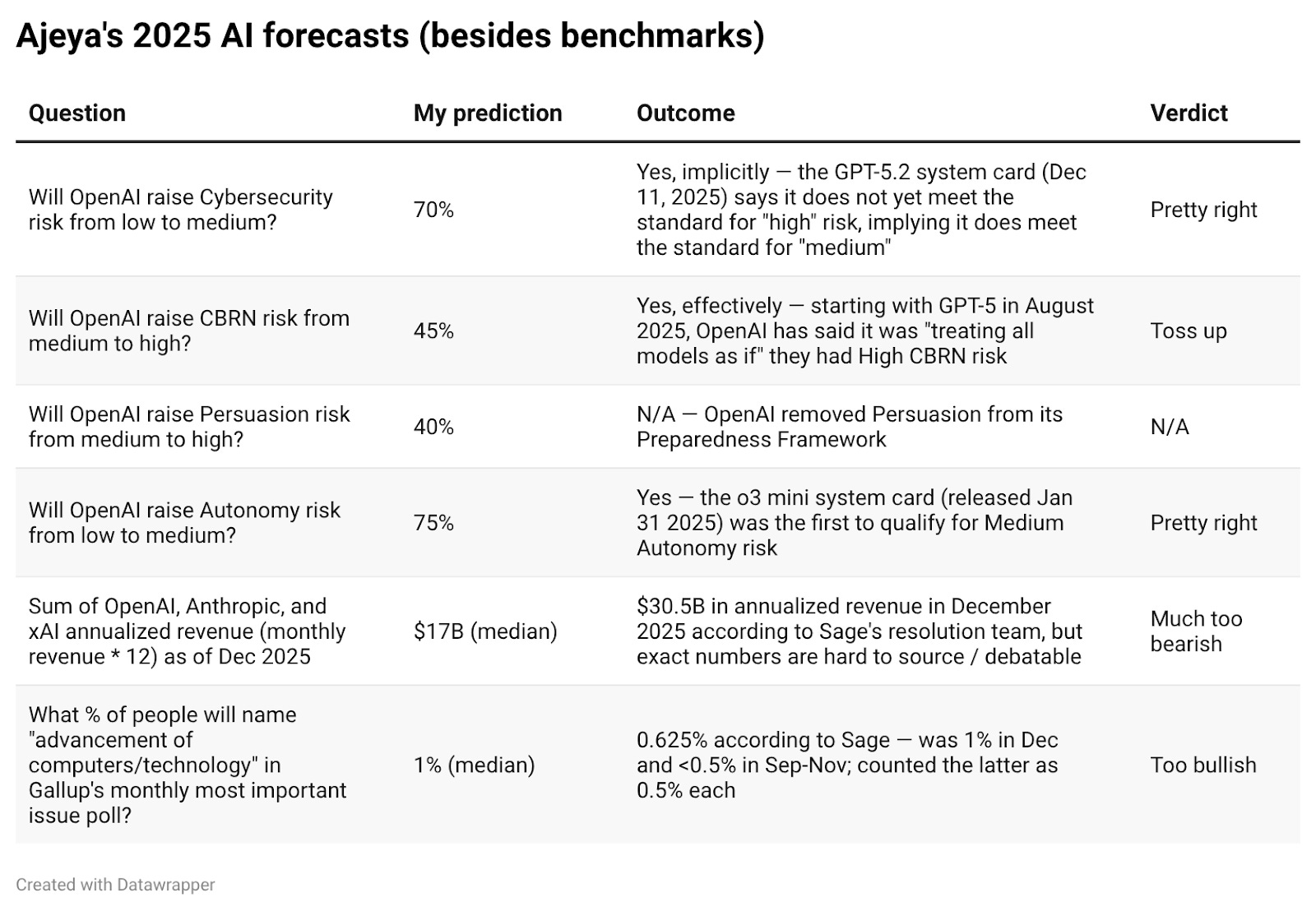
I’m not totally sure what’s up here,3 since I’ve heard from other sources that AI revenue has been roughly 3-4xing year on year. My best guess is the Sage resolution team pulled lowball reports for the 2024 baseline revenue; one friend who looked into it a bit said that EO2024 revenue was ~$6.4B rather than ~$4.5B as Sage reported. If true, this would make my prediction only somewhat too bearish.
Predictions for 2026
All these forecasts are evaluated as of 11:59 pm Pacific time on Dec 31 2026. I’ll start with giving my medians for some measurable quantities with pre-existing trends,:
50% METR time horizon: 24 hours. Currently, Claude Opus 4.5 has the longest reported 50% time horizon on this task suite, at 4h49m — meaning that METR’s model predicts it can to solve about half of the programming tasks that take a low-context human expert five hours (it’ll be able to solve a greater fraction of shorter tasks, and a smaller fraction of longer tasks). My median for the longest 50% time horizon reported as of Dec 31, 2026 is 24 hours (20th percentile 15 hours, 80th percentile is that it’s too long for METR to accurately bound in practice but probably around 40 hours in “reality”).
Note that to be able to measure even 24 hours accurately, METR would need to make new tasks, which they’re furiously working on now; this will somewhat change the task distribution, but I’m not thinking too hard about that now.
Epoch ECI: 169. This is a simple abstract model aggregating multiple benchmarks; it currently includes 37 distinct benchmarks but it can be extended to incorporate new ones. The current top score is 154, achieved by Gemini 3 Pro, and it has recently been growing at 15.5 points per year. The aggregated score is in abstract units, but you can back out an implicit prediction about particular benchmarks from that. For example, it seems like an ECI of 169 corresponds to a score of about 85% on Frontier Math Tiers 1-3 (though I expect the actual score to be a little lower, maybe 80%, since progress will probably slow down as it approaches saturation). My median prediction for Frontier Math Tier 4, and any other benchmark included in ECI that’s far from saturation, is whatever the ECI score implies it should be.
Annualized Dec AI revenue: $110 billion. The combined annualized revenue of OpenAI, Anthropic, and xAI (i.e. December revenue * 12) was $30.5 billion in December 2025, according to Sage. My median forecast of the same value for the month of Dec 2026 is $110 billion (20th percentile $60 billion, 80th percentile $300 billion). This is a ~5x increase, which is my current best guess for the actual increase from EO2024 to EO2025. [Edit 2/18: I noticed that $110 billion is not 5x $30.5 billion; guessing $110 billion was a typo and I meant to say $150 billion here]
Salience of AI as top issue: 2%. As of December 2025, 1% of people named “advancement of computers / technology” or equivalent as the most important issue in Gallup’s monthly polling. My median for December 2026 is 2% (20th percentile 1%, 80th percentile 7%).
Unfortunately this is a bit of an awkward metric — I’d rather track something like “median rank of AI among issues.” But I’m not aware of regular polling on that style of question.
Net AI favorability: +4%. David Shor’s recent polling found that optimism about AI beats pessimism by about 4.4 percentage points, with many people (24% still unsure). This was surprising to me given how salient concern about jobs and the environment and artists is in the discourse, but AI products are objectively pretty amazing and probably improving a lot of people’s lives. I think this will keep being true in 2026 so if a methodologically similar poll were conducted near the end of the year 2026 I don’t have much reason to think the result would be super different. My error bars are wide though, with more room on the downside than the upside: my 20th percentile is -10 points and my 80th percentile is +8 points.
Next, some vibes-y capability predictions. Here are a few tasks that I’m pretty sure AIs can’t do today but probably will be able to do as of Dec 31 2026.4 I’m about 80% on these, so I’m expecting to get four of these five predictions right. Note that some of these will be hard to directly test given the high specified inference budgets, in which case I’ll go with the best judgment of my friends who really understand current AI capabilities.
Game play. Play Pokemon or a similarly difficult video game at least as well as a typical ten year old, with no special fine-tuning and only a generic scaffold that doesn’t do any more hand-holding than the Claude Plays Pokemon scaffold.
Logistics. Organize a child’s birthday party for 20ish guests: find a good time that works for guests of honor, compose an invite email, keep track of RSVPs, order the right amount and diversity of food, order cake / decorations / piñata on the right theme, etc while abiding by relevant constraints like budget and dietary restrictions.
Video. From a high-level one-paragraph prompt, make a 4 minute short video with at least two characters where a series of somewhat-coherent plot beats happen and there’s no glaringly obvious visual incoherence or degeneracy.
Game design. From a high-level one paragraph prompt, make a decent visual novel (simple choose-your-own adventure game) that offers at least two hours of gameplay with a similar quality to the trashiest visual novel games you can find on Steam (that still work and have at least dozens of people buying them).
Math. Solve the hardest problem in the 2026 IMO (models got gold in the 2025 IMO but all failed to solve problem 6, which is typically the hardest problem in any IMO).
And tasks that I’m pretty sure AIs can’t do today and probably still won’t be able to do as of Dec 31 2026 (again expecting to get around 4 out of 5 correct).
Game play. [Edited for clarity 1/17]. Get a win rate in the upcoming Slay the Spire 2 comparable to a top player who’s been playing for 50 hours. I’m assuming the AI wasn’t pre-trained on guides for the game (if it is pre-trained on Slay the Spire 2, choose a similarly complicated game released later) and it has a generic harness and was not fine-tuned to play the game well, but does get a comparable amount of time to learn and practice the game as the human.
Logistics. Organize a typical-complexity wedding with 100 guests: find a suitable venue that meets the budget and constraints, go back and forth with caterers and photographers and other vendors, track RSVPs and maintain a seating chart, schedule toasts, etc.
Video. From a one-paragraph high-level prompt, make a >10 minute short film that’s hard for at least me (not a film buff) to easily distinguish from the kinds of short films that make it into film festivals (but don’t necessarily win awards there).
Game design. From a one-paragraph high-level prompt, make an original text adventure game that offers at least ten hours of gameplay that I consider to be as good as Counterfeit Monkey or an original visual novel that I consider to be decidedly better than Long Live the Queen.
Math. From scratch, write a paper that could get published in a top theoretical computer science or math journal / conference.
And lastly, some more extreme milestones I think are less likely still:
(near) Full automation of AI R&D: 10%. I currently think if you fired all the human technical staff working on AI R&D and tried to get AIs to do it all, technical progress would basically grind to a halt. My operationalization of “full automation” is: for whichever AI company is in the lead as of Dec 31, 2026, if you fired all its members of technical staff, its rate of technical progress on relevant benchmarks would be slowed down by less than 25% (this is a pretty arbitrary threshold, you can make the milestone more or less extreme by choosing a smaller or bigger number). Subjectively, I think it would feel like human researchers setting broad high-level multi-person-year AI research goals (e.g. “develop more sample-efficient optimization algorithms”) to teams of thousands of AI agents who run off and autonomously conduct dozens of experiments across hundreds of GPUs to make progress on the goal.
Top-human-expert dominating AI: 5%. This means an AI system that achieves ambitious long-term goals in any domain better than the world’s leading expert in that domain, using a comparable amount of time and cost — that is, a system simultaneously better at physics than Einstein, better at statecraft than Kissinger, better at entrepreneurship than [pick your favorite tech CEO I won’t name one], better at inventing nasty new viruses than whoever the world’s greatest virologist is…. The main pathway I see to this is automation of AI R&D sometime in mid-2026 → rapid intelligence explosion → TEDAI by end of year.
Self-sufficient AI: 2.5%. By this I mean a set of AI systems, together with enabling physical infrastructure, such that if humans all died then those AIs could “survive” and continuously grow their own population indefinitely (including repairing and maintaining the physical substrate they run on). The main pathway to this would probably involve quickly developing AIs somewhere around the TEDAI level, followed by those AIs quickly figuring out industrial production optimizations which allow it to orchestrate all the physical processes it needs to survive using the ~10,000-odd humanoid robots we currently produce or repurposing other actuators we already have lying around.
Unrecoverable loss of control: 0.5%. By this, I mean a situation in which some population of AI systems is operating autonomously without being subject to the control of any human or organization, and is robust against even highly-coordinated efforts by the US military to destroy it or bring it back under control. This is dominated by the possibility that AI R&D is fully automated in the middle of a year and this kicks off a rapid intelligence explosion that leads to very broadly superhuman AI. If such AIs were misaligned and had the goal of robustly evading human control, they could e.g. acquire a self-sufficient industrial base and defend it with advanced weapons.
Since some people act as if so-called “doomers” have to be committed to the prediction that recursively self-improving superintelligence will definitely kill us all in the next five minutes (and if it doesn’t then the whole concern is fake), I figured I would make it clear for the record that I think most likely nothing too crazy is going to happen by the end of 2026. And probably I’ll even make it another year without the AI-created otome game I’ve been pining for since the days of GPT-3.
But we genuinely might see some truly insane outcomes. And we are utterly unprepared for them. That’s to say nothing of the chance of insane outcomes in 2028 or 2030 or 2032. There’s a lot to do, and not much time.
Note that while all the other benchmarks are measured as an accuracy from 0% to 100%, METR's RE-Bench is a set of 7 open-ended ML engineering problems of the form "make this starter code better to improve its runtime / loss / win-rate," with scores normalized such that the provided starting code scores 0 and a strong reference solution scores 1, meaning you can get a score greater than 1 if you improve on the reference solution (and indeed current SOTA AIs do).
When the benchmark was released it was just called FrontierMath, and that’s how it’s referred to in the Sage survey. The original benchmark had three tiers of difficulty, and Epoch introduced a final harder tier in the summer of 2025.
At first I thought I got it so wrong because I misread the question as asking about total annual revenue rather than annualized December revenue (i.e., the monthly revenue in December times 12, which will naturally be a lot higher). I did in fact have that misconception, and it happened that total 2025 revenue was very close to my prediction of $17B. But then I realized that I must have just done the forecast by multiplying the 2024 baseline value (provided by Sage) by whatever multiple I thought was appropriate, and that number was the appropriate apples-to-apples comparison.
To make these predictions precise, you’d need to specify the maximum inference budget you allow the AI to use in its attempt. I don’t think specifying an exact budget generally matters too much for these predictions, because often either an AI won’t be able to do a task for any realistic budget, or else if it can do the task it’ll be able to do it very cheaply compared to humans. If there’s ambiguity, I’m imagining the AI getting to use an inference budget comparable to the amount you’d have to pay a human to do the same task.
Great post, ty!
The Pokemon prediction seems harder to me than the other 80% predictions, though maybe that's just because I saw an early Claude Plays Pokemon and was surprised by how many basic things tripped it up. Something something "real world complexities are surprisingly tricky to address"? I think recent models do substantially better, but still get tripped up in silly ways. Maybe this gets solved by continuous progress in a few areas of weakness, though: integrated image processing + longer context windows + better "notes-to-self" writing.
Math feels like the cleanest task, in the sense that there's no surprising / spiky environmental features to process, it's "natively" a thing you can do via text stream.
VN design also feels intuitively easy to me, maybe the main need here is again just bigger context windows and better self-management. I should play with Claude Code and see what trips it up here!
How do you plan to handle the incoming era of amazing video games on tap? Plug your ears with wax, or try to harness it for The Good by generating gripping edutainment for yourself about AI progress?
Although it is somewhat against the spirit of empirical laws whose effect comes from aggregating large # of independent causes, I would like to ask people here to speculate on what sort of human tasks are >24h time horizon but cannot be easily delegated to a group of humans each having 24h windows + notes from a manager (which can be replicated from 24h agents)
I assume such tasks must somehow involve learning + memory on task-specific subtasks of a form which is for example not easily learned/transferred from an instruction manual + short time of practice. For example, a physical task may ask you to become proficient at using a new type of machinery, whose proficiency cannot be easily attained from short-time-scale practice. But for cognitive tasks it is kind of more difficult for me to understand the type of task that requires experience-based learning. Perhaps if the task has a subtask which involves learning a novel subject/novel programming language etc.